


In this issue of the "what investors ought to know about…" series, we'll cover natural language processing (NLP), a tool that draws from the computer science and computational linguistics disciplines. In the last topic, we discussed knowledge graphs as the core of text analysis. And if knowledge graphs are the core of the data’s context, NLP is the transition to understanding the data.
What is natural language processing?
Natural language processing is an artificial intelligence (AI) technology that automates the data analysis of mined textual, unstructured data to include natural language understanding and natural language generation to simulate a human's ability to create language. It combines computational linguistics with machine learning and deep learning models, performing a special linguistic analysis by algorithms so a machine can "read" text.
Where is natural language processing used?
Today, various industries use NLP, from email filters to virtual assistants and search engines to chatbots. Here's a list of common ways natural language processing is used:
- Chatbots: Chatbots are computer programs that use NLP. They simulate human conversation by identifying a sentence's intent, determining suitable topics, keywords, and emotions, and calculating the best response based on the data's interpretation.
- Email filters: Email filters apply machine learning using many data samples to sort emails into the right inbox.
- Machine translation: Translation software like Google Translate or Microsoft Translator use NLP to translate text from one language to another, such as English to French.
- Natural language generation (NLG): NLG, a subfield of NLP, builds applications or computer systems that can automatically produce natural language texts of various types by using a semantic representation as input. Applications of NLG include question answering and text summarization.
- Predicting and autocorrecting text: Predictive text and autocorrect use NLP to recognize and recall commonly used words and names to make text suggestions and correct common errors.
- Search engines: Search engines like Google search use NLP machine learning to interpret a searcher's intent and provide relevant results. It can even suggest subjects and topics related to the query the searcher might be interested in.
- Virtual and voice assistants: Virtual assistants like Apple's Siri or Amazon's Alexa use NLP technology to understand and respond to voice requests. Speech-to-text can dictate messages and notes, and speech recognition can control everything from smartphone apps and smart speakers to thermostats and home security systems.
- Web sentiment analysis: Sentiment analysis automates classifying opinions in a text as positive, negative, or neutral. It's a method companies like SESAMm use to monitor sentiments like a brand's sentiment on the web and social media.
Why natural language processing is important to uncover financial-related alternative data
NLP is important because it helps resolve human language ambiguity in big datasets (big data). Languages are complex, diverse, and expressed in unlimited ways, from speaking hundreds of languages and dialects to having a unique set of grammar and syntax rules, slang, and terms for each. In text form, these variables are unstructured text. But with NLP, we can transform unstructured data into structured data and make sense of it.
Because of NLP's power, investors can research and analyze unstructured data from the web to gain insights into financial and ESG data. You can use this wealth of information to focus on systematic data processing, risk management, and alpha discovery through contexts, such as:
- Major global indices sentiment
- Euronext exchange sentiment
- Private company sentiment
- ESG risks for public and private companies worldwide
A quick overview of how natural language processing works at SESAMm
At SESAMm, we use named entity recognition (NER), which extracts the names of people, places, and other entities from text, and then named entity disambiguation (NED) to identify named entities based on their context and usage. For example, text referencing "Elon" could refer indirectly to Tesla through its CEO or a university in North Carolina. NED considers the context when classifying entities for an accurate match. Compared to simple pattern matching, which limits the number of possible matches, requires frequent manual adjustments, and can't distinguish homophones, NED is superior.
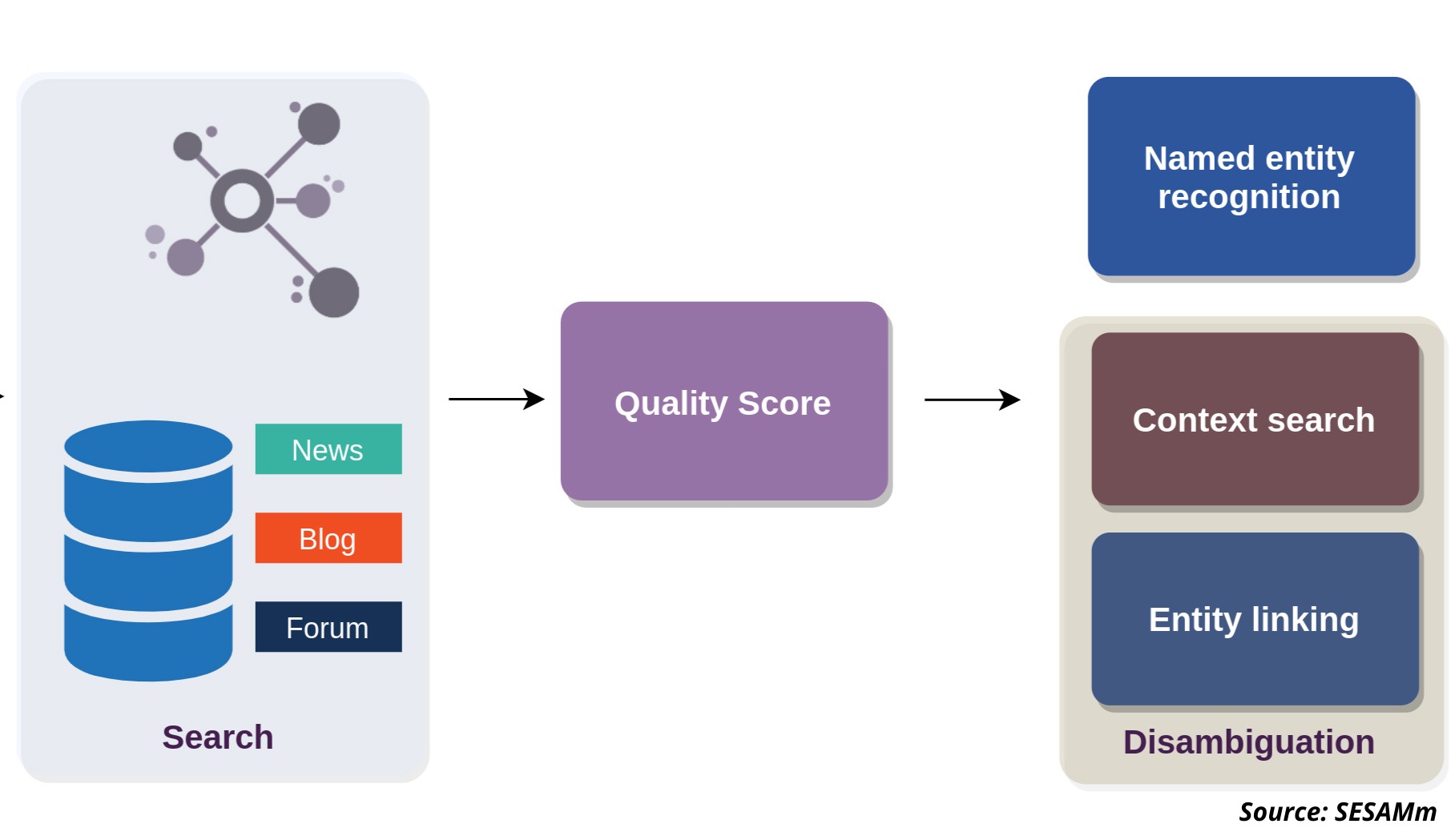
When identifying entities and creating actionable insights, SESAMm uses three other NLP tools: lemmatization and stemming, embeddings, and similarity. The lemmatization process normalizes a word into its base form (morphology) to help identify and aggregate entities. Embedding assigns the entity a numerical value to help analyze how words change meaning depending on context and understand the subtle differences between words that refer to the same concept—similarity measures whether two words, sentences, or objects are close to one another in meaning.
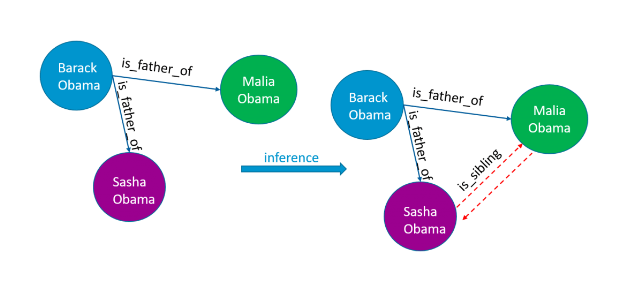
Of course, NLP couldn't function without the core of the text analytics process: knowledge graphs. A knowledge graph is a digital representation of a network of real-world entities, the foundation of a search engine or question-answering service. This structured data model puts the schema in context through semantic metadata and linking, providing a framework for analytics, data integration, sharing, and unification. In other words, it's like a map and legend, with the legend labeling the concepts, entities, and events and the map connecting and identifying their relationships. These details are stored in a graph database and visualized as a graph representation, hence the term knowledge graph.
SESAMm's natural language processing platform for investment research and analysis
SESAMm is the leading provider of natural language processing and machine learning solutions and analytics for investment firms and corporations.
Our AI and NLP platform, TextReveal®:
- Analyzes text in billions of web-based articles and messages
- Generates investment insights and ESG analysis used in systematic trading, fundamental research, risk management, and sustainability analysis
- Enables a more quantitative approach to leveraging the value of web data that's less prone to human bias
- Addresses a growing need in public and private investment sectors for robust, timely, and granular sentiment and ESG data
For a personal demo, contact us today.




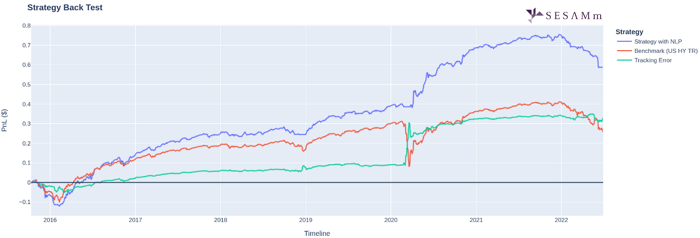




.png)